Triton DropConnect Kernel
INFO
Code is available at TritonDeepLearningKernel.
Deep learning tools have gained tremendous attention in applied machine learning. However such tools for regression and classification do not capture model uncertainty. In comparison, Bayesian models offer a mathematically grounded framework to reason about model uncertainty but usually come with a prohibitive computational cost.

Gal et al1. showed that Dropout, a well-known regularization technique, is mathematically equivalent to approximate variational inference in the deep Gaussian process. DropConnect, known as the generalized version of Dropout showed superiority in achieving higher prediction accuracy and more precise uncertainty estimation in different ML tasks2.
However, the most intuitive way that is commonly used to write the DropConnect function is not mathematically correct when calculating batched inputs!

The unbatched DropConnect is given by \(\left({D^\intercal\odot W}^\intercal\right)\times\ X=Y\) where \(\odot\) is the Hadamard product used to apply dropout mask \(D\) to the weight \(W\).
Write the DropConnect function above in PyTorch code:
p = 0.5
weight = F.dropout(weight, p, training=True) * p
mul = torch.matmul(x, weight)
We first apply a dropout mask to the weight and then use matmul to calculate matrix multiplication with the input x. If we directly use this code for batched input:

\(M\) is the batch size, and the same dropout mask \(D\) is applied to different batches. We can immediately notice the problem that for different inputs, they are using the same set of weights for calculation. The behavior of batched and unbatched inputs is different, since for unbatched inputs, the dropout masks are different at each inference (That’s also what it should be).

We need a dropout mask with shape [M,N,K] to apply different dropout for batched inputs. Also, we need to manually broadcast the weight to shape [M,N,K] and reshape the input to [M,K,1]. The code is:
def dropconnect(x: torch.Tensor, weight: torch.Tensor, bias: torch.Tensor):
weight = weight.T
squeezeloc = x.dim()-1
x = x.unsqueeze(squeezeloc)
weight = torch.broadcast_to(weight, (*x.shape[0:-2], *weight.shape))
weight = F.dropout(weight, 0.5, training=True) * 0.5
mul = torch.matmul(x, weight).squeeze(squeezeloc)
out = mul + bias.view([1]*squeezeloc + [-1])
return out
The above DropConnect is mathematically correct as we want. However, it has significant performance overhead:
- It increase M times elementwise multiply.
- The matrix multiplication of \(W^\intercal\times\ X\) becomes to a shape \([M,N,K]\times[M,K,1]\) which is more difficult for hardware to process compared with the original shape \([N,K]\times[K,M]\).
- The memory usage is increased for 2M times for storing the broadcasted masks and weight during forward process.
Actually, PyTorch provided a very good tool to increase the performance of customized operations in torch2.0 which is the torch.compile. It can compile the customized operations to triton codes and automatically fuse the kernels. And it works for the dropconnect function, accelerated the execution and reduced the memory usage. However, it still needs to run the original code in eager mode for once to perform the analyze.
The problem is, the original dropconnect function will use up all the GPU memory and make the program fail. Additionally, since the dropconnect function will be reused for many times. It’s worth to write a kernel manually for optimal performance.
Inspired by the Low-Memory Dropout — Triton documentation. One can use the seeded random number generation to generate the dropout mask instead of storing it in the memory.

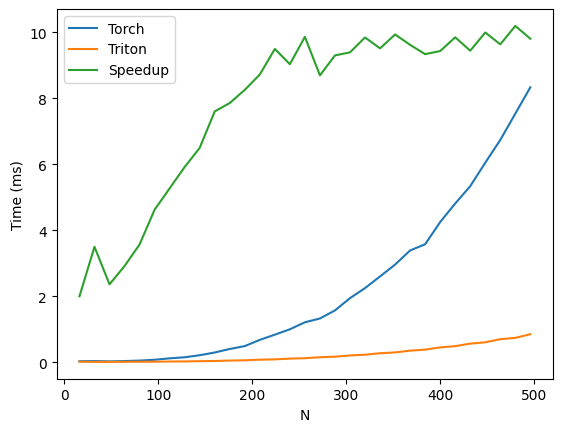
Benchmarks

References
[1] Gal, Y., & Ghahramani, Z. (2016). Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. 33rd International Conference on Machine Learning, ICML 2016, 3, 1651–1660. https://proceedings.mlr.press/v48/gal16.html
[2] Mobiny, A., Yuan, P., Moulik, S. K., Garg, N., Wu, C. C., & van Nguyen, H. (2021). DropConnect is effective in modeling uncertainty of Bayesian deep networks. Scientific Reports 2021 11:1, 11(1), 1–14. https://doi.org/10.1038/s41598-021-84854-x
If you found this useful, please cite this as:
Xiao, Zhihua (Nov 2024). Triton DropConnect Kernel. https://forkxz.github.io/blog/2024/DropConnect/.
or as a BibTeX entry:
@article{xiao2024triton-dropconnect-kernel,
title = {Triton DropConnect Kernel},
author = {Xiao, Zhihua},
year = {2024},
month = {Nov},
url = {https://forkxz.github.io/blog/2024/DropConnect/}
}
Enjoy Reading This Article?
Here are some more articles you might like to read next: