Publications
2025
-
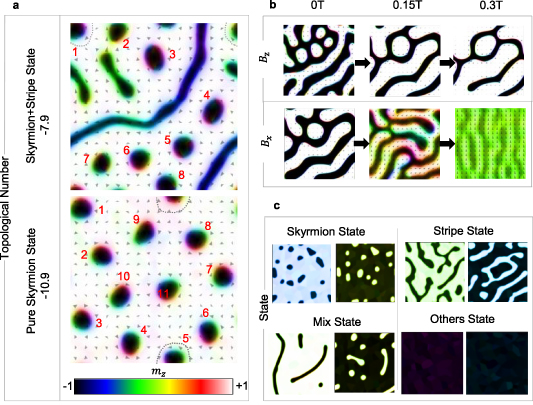 Reinforcement Learning for Optimizing Magnetic Skyrmion CreationXiuzhu Wang , Zhihua Xiao, Xuezhao Wu , Qiming Shao , and Yan ZhouNanotechnology, 2025
Reinforcement Learning for Optimizing Magnetic Skyrmion CreationXiuzhu Wang , Zhihua Xiao, Xuezhao Wu , Qiming Shao , and Yan ZhouNanotechnology, 2025The topologically stabilized quasi-particle skyrmion is one of the most significant spin structures. Its unique physical properties—such as stability, nanoscale size, and efficient manipulability—make it a promising candidate for applications in high-density data storage, low-power in-memory computing, and neuromorphic devices. Skyrmions are typically generated from ferromagnetic states using field-tuning or current-tuning methods, which involve applying magnetic fields with varying gradients and sequences or spin-current pulses with specific amplitudes and polarizations. However, the complexity of these applied field or current sequences during skyrmion generation often leads to numerous intermediate phases, making the process repetitive and heavily reliant on trial and error. To address this challenge, we propose a phase-control method based on reinforcement learning (RL) to optimize field control for skyrmion generation. The RL framework incorporates a carefully designed reward system, guided by physical insights, that considers the topological number and feature states while encouraging diverse field-tuning modes. Training results demonstrate that the network can progressively learn and optimize the field sequences required for skyrmion generation. Once trained, the network is capable of autonomously and reliably generating skyrmions, significantly reducing the need for manual intervention and trial-and-error adjustments. This approach has broader potential applications, including the generation of other spintronic structures such as chiral domain walls and magnetic vortices. It represents a valuable contribution to AI-driven spintronic simulations, bridging the gap between computational models and experimental implementations, and advancing the development of next-generation spintronic technologies.
-
 Spintronic Foundation Cells for Scalable Unconventional ComputingZhihua Xiao, and Qiming ShaoIn 2025 9th IEEE Electron Devices Technology & Manufacturing Conference (EDTM) , 2025
Spintronic Foundation Cells for Scalable Unconventional ComputingZhihua Xiao, and Qiming ShaoIn 2025 9th IEEE Electron Devices Technology & Manufacturing Conference (EDTM) , 2025With the ending of Moore’s law and the thriving of unconventional computing, there is a growing demand for the development of emerging device technologies. However, it is anticipated that completely replacing complementary metal-oxide-semiconductor (CMOS) technology will not be feasible in the foreseeable future. Thus, in this paper, we showed how one of the emerging technologies, spintronic devices can be integrated with CMOS technologies as the foundation cells for scalable unconventional computing.
-
 A 40nm 4Mb High-Reliability STT-MRAM Achieving 18ns Write-Time and 94.9% Wafer-Level-Die-Yield Across-55° C-to-125° CYaoru Hou , Haoran Du , Jiongzhe Su , Yibo Liu , Zhenghan Fang , Jia-le Cui , Shuyu Wang , Chenxing Liu-Sun , Xuezhao Wu , Zhihua Xiao, and othersIn 2025 IEEE Custom Integrated Circuits Conference (CICC) , 2025
A 40nm 4Mb High-Reliability STT-MRAM Achieving 18ns Write-Time and 94.9% Wafer-Level-Die-Yield Across-55° C-to-125° CYaoru Hou , Haoran Du , Jiongzhe Su , Yibo Liu , Zhenghan Fang , Jia-le Cui , Shuyu Wang , Chenxing Liu-Sun , Xuezhao Wu , Zhihua Xiao, and othersIn 2025 IEEE Custom Integrated Circuits Conference (CICC) , 2025STT-MRAM emerges as one of the promising candidates for next-generation non-volatile memory, offering versatility across diverse applications [1]–[6]. However, designing high-reliability MRAM for automotive and aerospace applications is particularly challenging. It demands operation across wide temperature ranges while balancing retention, write speed, and endurance in extreme environments [7]. It remains a great challenge for wide-temperature design of reliable STT-MRAM operating from -55°C to 125°C with high wafer-level die yield: (1) Operations in MRAM chip necessitate multiple input voltages that are sensitive to temperature and process variations. Despite this critical requirement, a thorough analysis of on-chip power delivery architectures has been largely overlooked in prior MRAM designs. (2) Wide-temperature MRAM encounters breakdown and endurance degradation at low temperature, significantly affecting its reliability and suitability in extreme environments [8]. (3) Traditional MRAM yield analysis, primarily based on single-device tests or MT J arrays, inadequately considers die-to-die variations, circuit-system interactions, and real-world operating conditions, leading to statistically insignificant results.
-
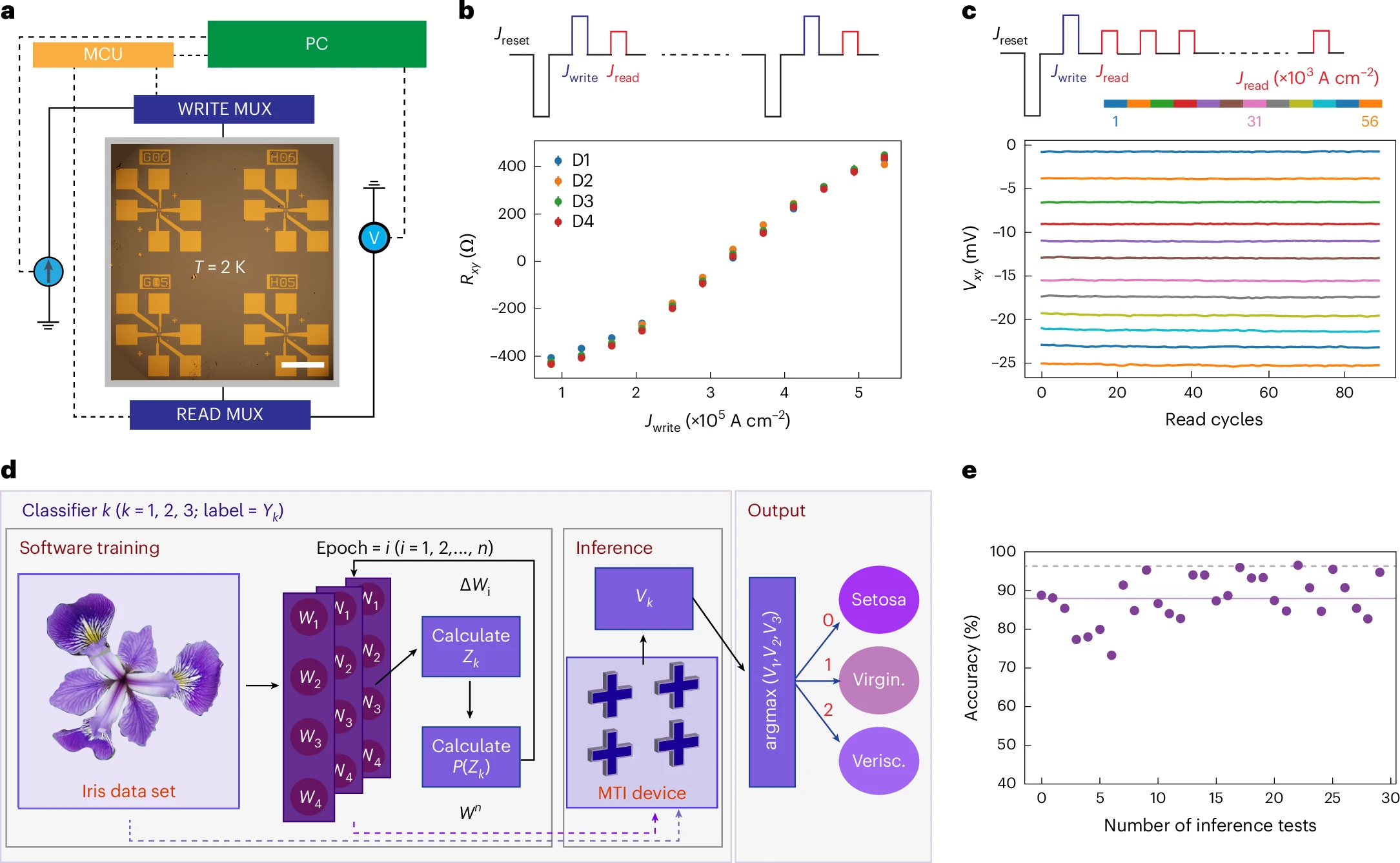 Cryogenic in-memory computing using magnetic topological insulatorsYuting Liu , Albert Lee , Kun Qian , Peng Zhang , Zhihua Xiao, Haoran He , Zheyu Ren , Shun Kong Cheung , Ruizi Liu , Yaoyin Li , and othersNature Materials, 2025
Cryogenic in-memory computing using magnetic topological insulatorsYuting Liu , Albert Lee , Kun Qian , Peng Zhang , Zhihua Xiao, Haoran He , Zheyu Ren , Shun Kong Cheung , Ruizi Liu , Yaoyin Li , and othersNature Materials, 2025Machine learning algorithms have proven to be effective for essential quantum computation tasks such as quantum error correction and quantum control. Efficient hardware implementation of these algorithms at cryogenic temperatures is essential. Here we utilize magnetic topological insulators as memristors (termed magnetic topological memristors) and introduce a cryogenic in-memory computing scheme based on the coexistence of a chiral edge state and a topological surface state. The memristive switching and reading of the giant anomalous Hall effect exhibit high energy efficiency, high stability and low stochasticity. We achieve high accuracy in a proof-of-concept classification task using four magnetic topological memristors. Furthermore, our algorithm-level and circuit-level simulations of large-scale neural networks demonstrate software-level accuracy and lower energy consumption for image recognition and quantum state preparation compared with existing magnetic memristor and complementary metal-oxide-semiconductor technologies. Our results not only showcase a new application of chiral edge states but also may inspire further topological quantum-physics-based novel computing schemes.
2024
-
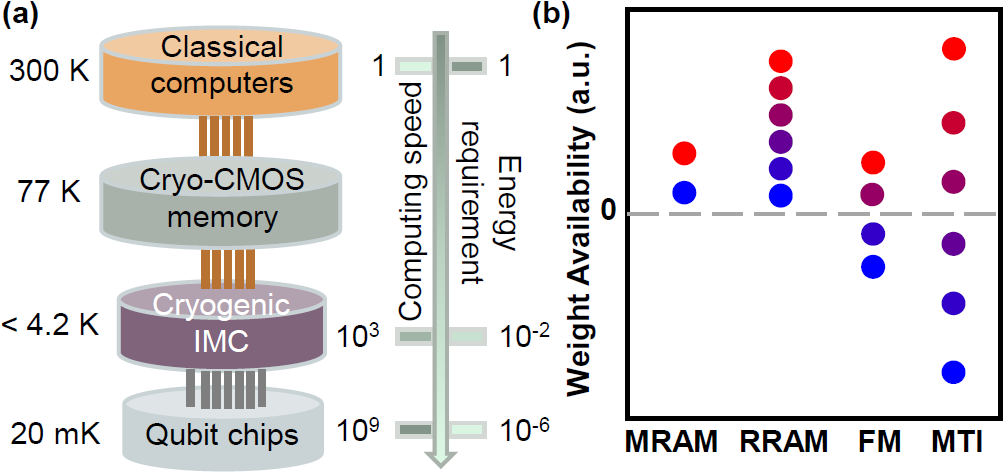 Cryogenic In-Memory Computing Circuits with Giant Anomalous Hall Current in Magnetic Topological Insulators for Quantum ControlKun Qian , Albert Lee , Zhihua Xiao, H. He , S. Cheung , Yuting Liu , F.P. Nugraha , and Qiming ShaoIn 2024 IEEE International Electron Devices Meeting (IEDM) , 2024
Cryogenic In-Memory Computing Circuits with Giant Anomalous Hall Current in Magnetic Topological Insulators for Quantum ControlKun Qian , Albert Lee , Zhihua Xiao, H. He , S. Cheung , Yuting Liu , F.P. Nugraha , and Qiming ShaoIn 2024 IEEE International Electron Devices Meeting (IEDM) , 2024Cryogenic in-memory computing, operating at temperatures below 4.2 K, offers high performance and energy efficiency in computation-intensive environments, especially for quantum controls. Spintronic memristors based on anomalous Hall effect (AHE) can be utilized with advantages of multi-bit bipolar weights and nearly unlimited endurance. However, there exists two major challenges in realizing an AHE-based neural network (NN): first, anomalous Hall resistances RH typically range in the order of a few ohms in conventional ferromagnets; second, signal-to-noise ratio of summation and read disturbance can lead to errors in NN operation. In this work, we demonstrate large RH of 12 kΩ at 2 K using a magnetic topological insulator (MTI) utilizing the quantum AHE, and for the first time, propose and experimentally verify the multiply-and-accumulate operation of a transverse-read Hall-current based neural network (Hall NN). Simulation of the proposed MTI Hall NN achieves matching accuracy to a full-precision network in the noisy qubit state preparation task. Compared with the MRAM NN, the MTI NN features a 90% lower write energy and 10 times higher TOPS/W showing the promise of MTI Hall NNs.
-
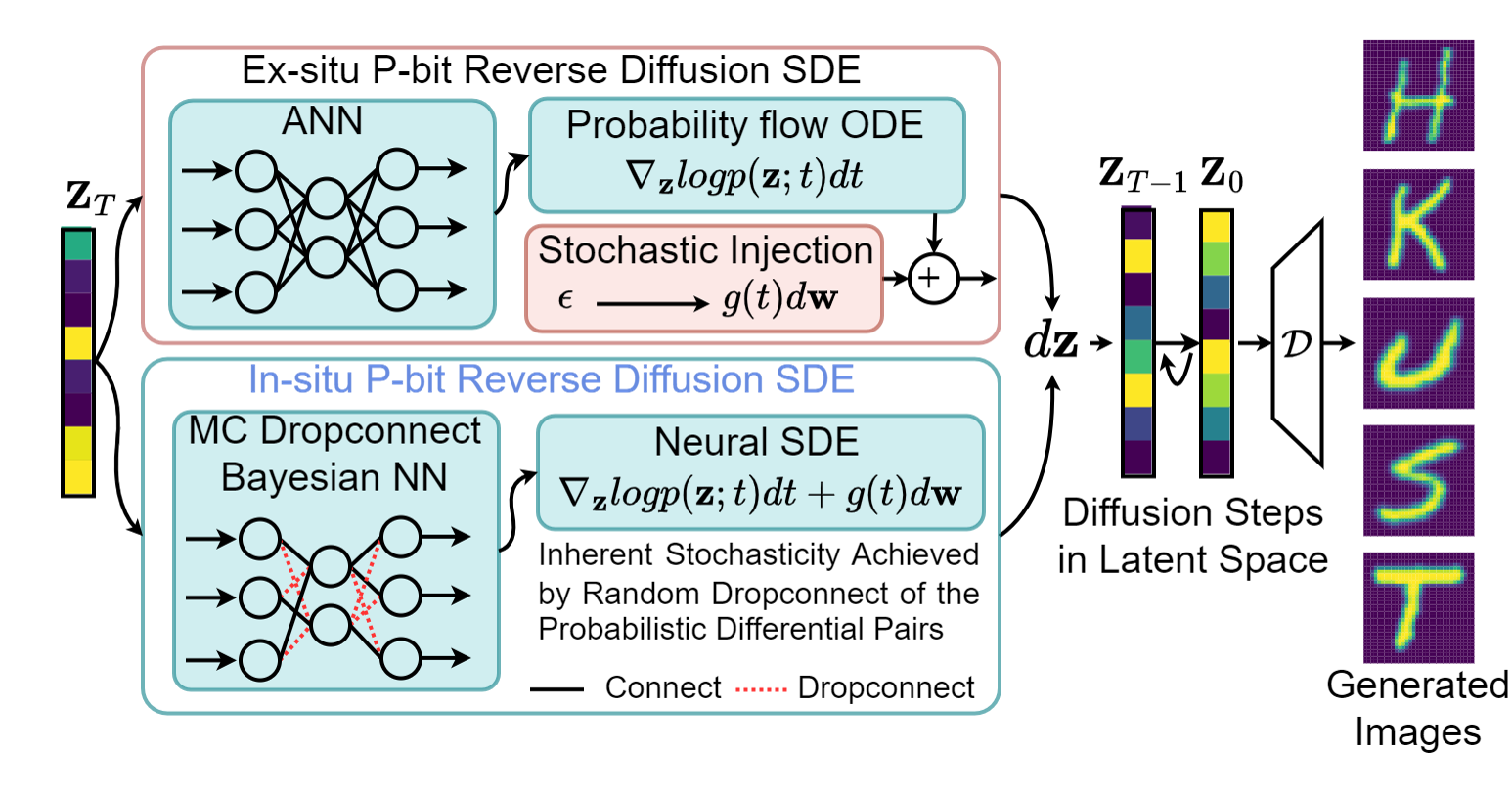 In-Memory Neural Stochastic Differential Equations with Probabilistic Differential Pair Achieved by In-Situ P-Bit Using CMOS Integrated Voltage-Controlled Magnetic Tunnel JunctionsZhihua Xiao, Yaoru Hou , Zihan Tong , Yicheng Jiang , Yiyang Zhang , Xuezhao Wu , Albert Lee , Di Wu , Hao Cai , and Qiming ShaoIn 2024 IEEE International Electron Devices Meeting (IEDM) , 2024
In-Memory Neural Stochastic Differential Equations with Probabilistic Differential Pair Achieved by In-Situ P-Bit Using CMOS Integrated Voltage-Controlled Magnetic Tunnel JunctionsZhihua Xiao, Yaoru Hou , Zihan Tong , Yicheng Jiang , Yiyang Zhang , Xuezhao Wu , Albert Lee , Di Wu , Hao Cai , and Qiming ShaoIn 2024 IEEE International Electron Devices Meeting (IEDM) , 2024The probabilistic bit (P-bit) is the core of probabilistic computing. We propose a novel in-situ P-bit compatible with compute-in-memory (CIM) schemes using voltage-controlled magnetic tunnel junctions (MTJs) to eliminate the generation-sample-transfer-compute paradigm of current P-bits. The conventional approach of sampling and transferring random sequences between separate P-bits and computing units reintroduces the memory bottleneck seen in von Neumann architectures, thereby limiting the efficiency of probabilistic computing. By pairing a data-bit and a P-bit as a probabilistic differential pair in a crossbar array, we enable random sequences to be directly utilized for computing. This generationcompute scheme eradicates the sampling and transfer costs associated with previous probabilistic computing methods. Full reuse of devices in the differential cells allows for probabilistic CIM with a large number of P-bits and high parallelism, suitable for real-world probabilistic computing tasks. We demonstrated in-memory neural stochastic differential equations for the reverse diffusion process in generative models. The results shows that without the bottlenecks, in-situ P-bit throughput is 6× faster and 2.19× more efficient than ex-situ P-bits using the same technology. Compared to other devices and schemes, the proposed scheme is 3× faster than state-of-the-art CMOS designs and 1.36× more energy efficient.
-
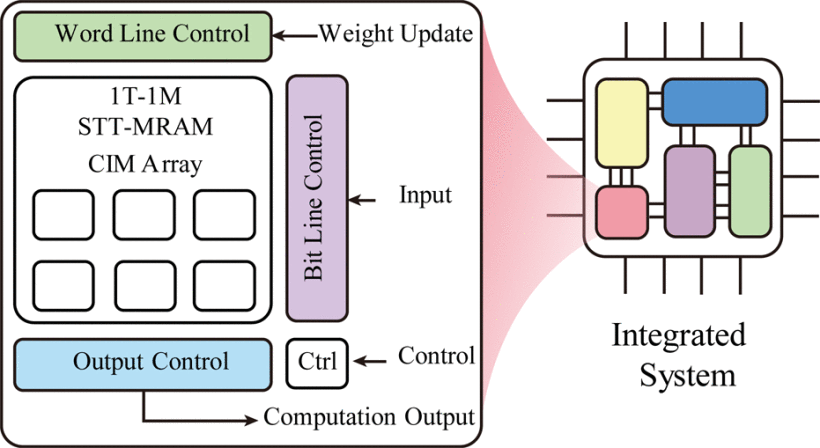
 Adapting magnetoresistive memory devices for accurate and on-chip-training-free in-memory computingZhihua Xiao, Vinayak Bharat Naik , Jia Hao Lim , Yaoru Hou , Zhongrui Wang , and Qiming ShaoScience Advances, 2024
Adapting magnetoresistive memory devices for accurate and on-chip-training-free in-memory computingZhihua Xiao, Vinayak Bharat Naik , Jia Hao Lim , Yaoru Hou , Zhongrui Wang , and Qiming ShaoScience Advances, 2024Memristors have emerged as promising devices for enabling efficient multiply-accumulate (MAC) operations in crossbar arrays, crucial for analog in-memory computing (AiMC). However, variations in memristors and associated circuits can affect the accuracy of analog computing. Typically, this is mitigated by on-chip training, which is challenging for memristors with limited endurance. We present a hardware-software codesign using magnetic tunnel junction (MTJ)–based AiMC off-chip calibration that achieves software accuracy without costly on-chip training. Hardware-wise, MTJ devices exhibit ultralow cycle-to-cycle variations, as experimentally evaluated over 1 million mass-produced devices. Software-wise, leveraging this, we propose an off-chip training method to adjust deep neural network parameters, achieving accurate AiMC inference. We validate this approach with MAC operations, showing improved transfer curve linearity and reduced errors. By emulating large-scale neural network models, our codesigned MTJ-based AiMC closely matches software baseline accuracy and outperforms existing off-chip training methods, highlighting MTJ’s potential in AI tasks.
-
 Tunable intermediate states for neuromorphic computing with spintronic devicesShun Kong Cheung , Zhihua Xiao, Jiacheng Liu , Zheyu Ren , and Qiming ShaoJournal of Applied Physics, Jul 2024
Tunable intermediate states for neuromorphic computing with spintronic devicesShun Kong Cheung , Zhihua Xiao, Jiacheng Liu , Zheyu Ren , and Qiming ShaoJournal of Applied Physics, Jul 2024In the pursuit of advancing neuromorphic computing, our research presents a novel method for generating and precisely controlling intermediate states within heavy metal/ferromagnet systems. These states are engineered through the interplay of a strong in-plane magnetic field and an applied charge current. We provide a method for fine-tuning these states by introducing a small out-of-plane magnetic field, allowing for the modulation of the system’s probabilistic response to varying current levels. We also demonstrate the implementation of a spiking neural network (SNN) with a tri-state spike timing-dependent plasticity (STDP) learning rule using our devices. Our research furthers the development of spintronics and informs neural system design. These intermediate states can serve as synaptic weights or neuronal activations, paving the way for multi-level neuromorphic computing architectures.
-
 Strongly temperature-dependent spin–orbit torque in sputtered WTexZheyu Ren , Ruizi Liu , Shunkong Cheung , Kun Qian , Xuezhao Wu , Zhihua Xiao, Zihan Tong , Jiacheng Liu , and Qiming ShaoJournal of Applied Physics, Jul 2024
Strongly temperature-dependent spin–orbit torque in sputtered WTexZheyu Ren , Ruizi Liu , Shunkong Cheung , Kun Qian , Xuezhao Wu , Zhihua Xiao, Zihan Tong , Jiacheng Liu , and Qiming ShaoJournal of Applied Physics, Jul 2024Topological materials have shown promising potential in the spintronics application due to their conspicuous efficiency of charge-to-spin conversion. Our research investigates the temperature-dependent spin–orbit torque (SOT) from sputtered WTe x. We reveal a strong temperature dependence of SOT and realize the current-induced SOT switching of WTe x with perpendicular magnetic anisotropy structure under a wide range of 12 K to room temperature. Our findings reveal the temperature dependence of sputtered WTe x and may pave the way for the spintronics application of semimetals under cryogenic temperature.
2022
-
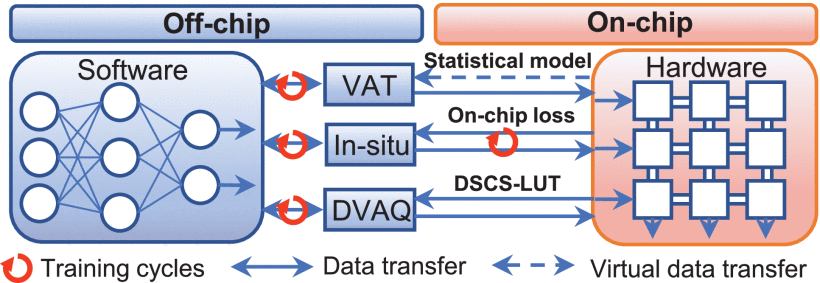 Device Variation-Aware Adaptive Quantization for MRAM-based Accurate In-Memory Computing Without On-chip TrainingZhihua Xiao, Vinayak Bharat Naik , Shun Kong Cheung , Jia Hao Lim , Jae-Hyun Kwon , Zheyu Ren , Zhongrui Wang , and Qiming ShaoIn 2022 International Electron Devices Meeting (IEDM) , Jul 2022
Device Variation-Aware Adaptive Quantization for MRAM-based Accurate In-Memory Computing Without On-chip TrainingZhihua Xiao, Vinayak Bharat Naik , Shun Kong Cheung , Jia Hao Lim , Jae-Hyun Kwon , Zheyu Ren , Zhongrui Wang , and Qiming ShaoIn 2022 International Electron Devices Meeting (IEDM) , Jul 2022Hardware-accelerated artificial intelligence with emerging nonvolatile memory such as spin-transfer torque-magneto-resistive random-access memory (STT-MRAM) is pushing both the algorithm and hardware to their design limits. The restrictions for analog-based in-memory computing (IMC) include the device variation, IR drop effect due to low resistance of STT-MRAM and read disturbance in the memory array at the advanced technology node. On-chip hybrid training can recover the inference accuracy but at the cost of many training epochs, reducing the available lifetime for updating cycles needed for on-chip inference. In this work, we show the unique feature of device variations in the foundry STT-MRAM array and propose a software-hardware cross-layer co-design scheme for STT-MRAM IMC. By sensing device level variations, we can leverage them for more conductance levels to adaptively quantize the deep neural networks (DNNs). This device variation-aware adaptive quantization (DVAQ) scheme enables a DNN inference accuracy comparable to on-chip hybrid training without on-chip training. Besides, this DVAQ scheme greatly reduces IR drop effects. Overall, the DVAQ allows one to achieve less than a 1% accuracy drop compared with in-situ training under 40 % device variation/noise without on-chip training in several DNN applications.
-
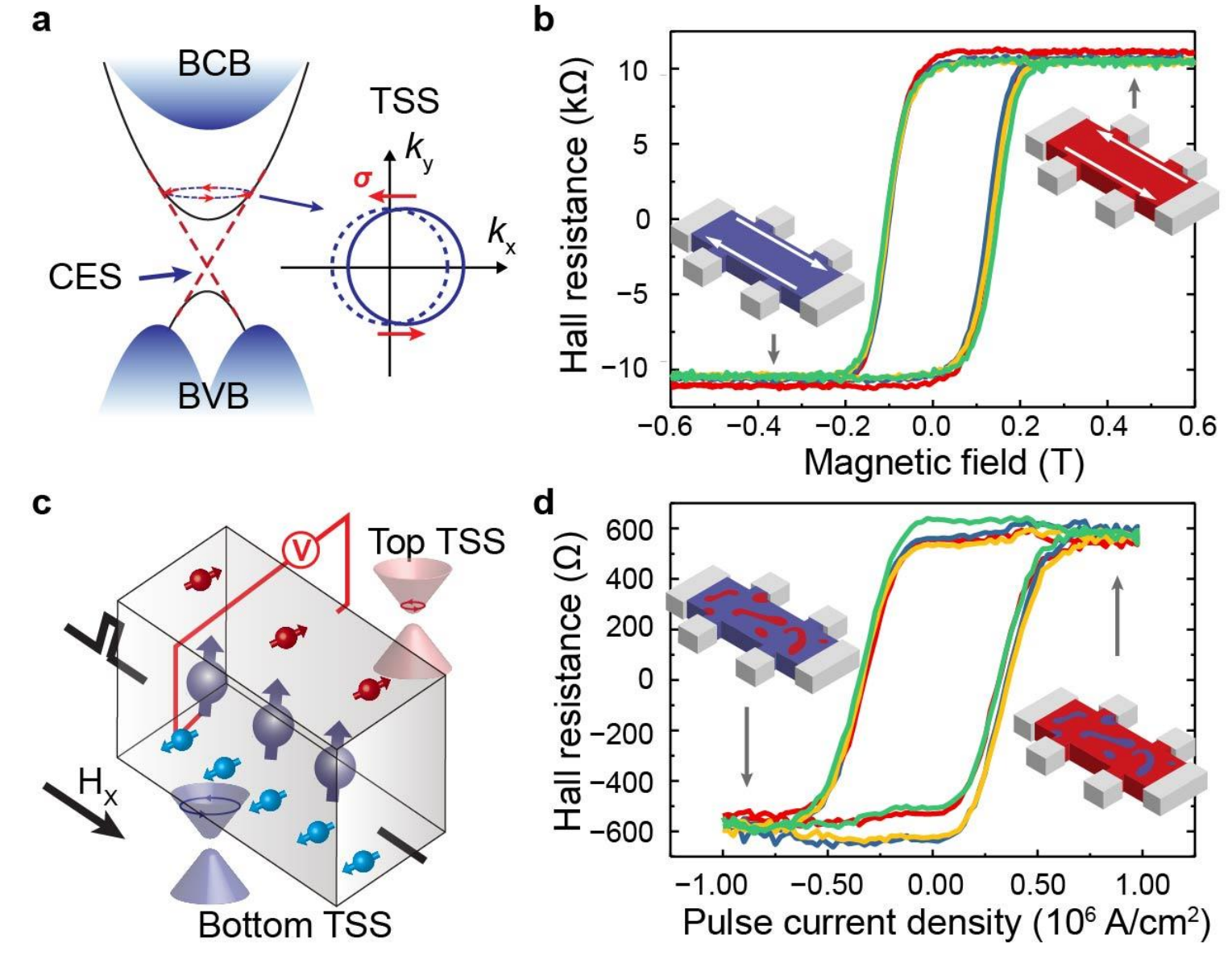 Cryogenic in-memory computing using tunable chiral edge statesYuting Liu , Albert Lee , Kun Qian , Peng Zhang , Haoran He , Zheyu Ren , Shun Kong Cheung , Yaoyin Li , Xu Zhang , Zichao Ma , and othersarXiv preprint arXiv:2209.09443, Jul 2022
Cryogenic in-memory computing using tunable chiral edge statesYuting Liu , Albert Lee , Kun Qian , Peng Zhang , Haoran He , Zheyu Ren , Shun Kong Cheung , Yaoyin Li , Xu Zhang , Zichao Ma , and othersarXiv preprint arXiv:2209.09443, Jul 2022Energy-efficient hardware implementation of machine learning algorithms for quantum computation requires nonvolatile and electrically-programmable devices, memristors, working at cryogenic temperatures that enable in-memory computing. Magnetic topological insulators are promising candidates due to their tunable magnetic order by electrical currents with high energy efficiency. Here, we utilize magnetic topological insulators as memristors (termed magnetic topological memristors) and introduce a chiral edge state-based cryogenic in-memory computing scheme. On the one hand, the chiral edge state can be tuned from left-handed to right-handed chirality through spin-momentum locked topological surface current injection. On the other hand, the chiral edge state exhibits giant and bipolar anomalous Hall resistance, which facilitates the electrical readout. The memristive switching and reading of the chiral edge state exhibit high energy efficiency, high stability, and low stochasticity. We achieve high accuracy in a proof-of-concept classification task using four magnetic topological memristors. Furthermore, our algorithm-level and circuit-level simulations of large-scale neural networks based on magnetic topological memristors demonstrate a software-level accuracy and lower energy consumption for image recognition and quantum state preparation compared with existing memristor technologies. Our results may inspire further topological quantum physics-based novel computing schemes.
2020
-
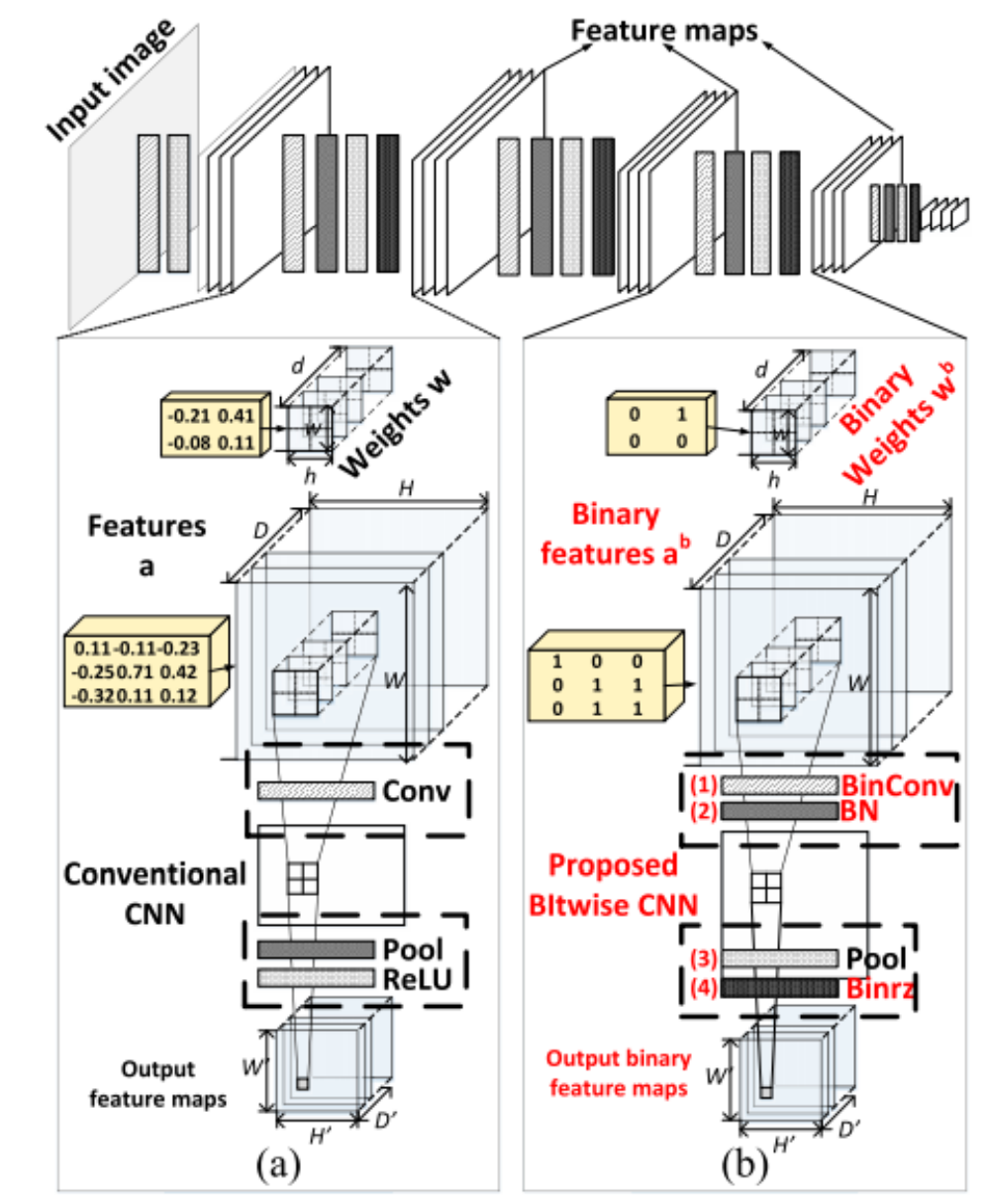 Energy-efficient machine learning accelerator for binary neural networksWei Mao , Zhihua Xiao, Peng Xu , Hongwei Ren , Dingbang Liu , Shirui Zhao , Fengwei An , and Hao YuIn Proceedings of the 2020 on Great Lakes Symposium on VLSI , Jul 2020
Energy-efficient machine learning accelerator for binary neural networksWei Mao , Zhihua Xiao, Peng Xu , Hongwei Ren , Dingbang Liu , Shirui Zhao , Fengwei An , and Hao YuIn Proceedings of the 2020 on Great Lakes Symposium on VLSI , Jul 2020Binary neural network (BNN) has shown great potential to be implemented with power efficiency and high throughput. Compared with its counterpart, the convolutional neural network (CNN), BNN is trained with binary constrained weights and activations, which are more suitable for edge devices with less computing and storage resource requirements. In this paper, we introduce the BNN characteristics, basic operations and the binarized-network optimization methods. Then we summarize several accelerator designs for BNN hardware implementation by using three mainstream structures, i.e., ReRAM-based crossbar, FPGA and ASIC. Based on the BNN characteristics and hardware custom designs, all these methods achieve massively parallelized computations and highly pipelined data flow to enhance its latency and throughput performance. In addition, the intermediate data with the binary format are stored and processed on chip by constructing the computing-in-memory (CIM) architecture to reduce the off-chip communication costs, including power and latency.
-
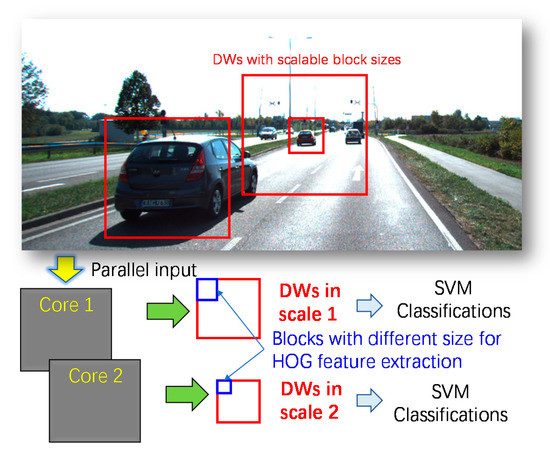 A multi-core object detection coprocessor for multi-scale/type classification applicable to IoT devicesPeng Xu , Zhihua Xiao, Xianglong Wang , Lei Chen , Chao Wang , and Fengwei AnSensors, Jul 2020
A multi-core object detection coprocessor for multi-scale/type classification applicable to IoT devicesPeng Xu , Zhihua Xiao, Xianglong Wang , Lei Chen , Chao Wang , and Fengwei AnSensors, Jul 2020Power efficiency is becoming a critical aspect of IoT devices. In this paper, we present a compact object-detection coprocessor with multiple cores for multi-scale/type classification. This coprocessor is capable to process scalable block size for multi-shape detection-window and can be compatible with the frame-image sizes up to 2048 × 2048 for multi-scale classification. A memory-reuse strategy that requires only one dual-port SRAM for storing the feature-vector of one-row blocks is developed to save memory usage. Eventually, a prototype platform is implemented on the Intel DE4 development board with the Stratix IV device. The power consumption of each core in FPGA is only 80.98 mW.
-
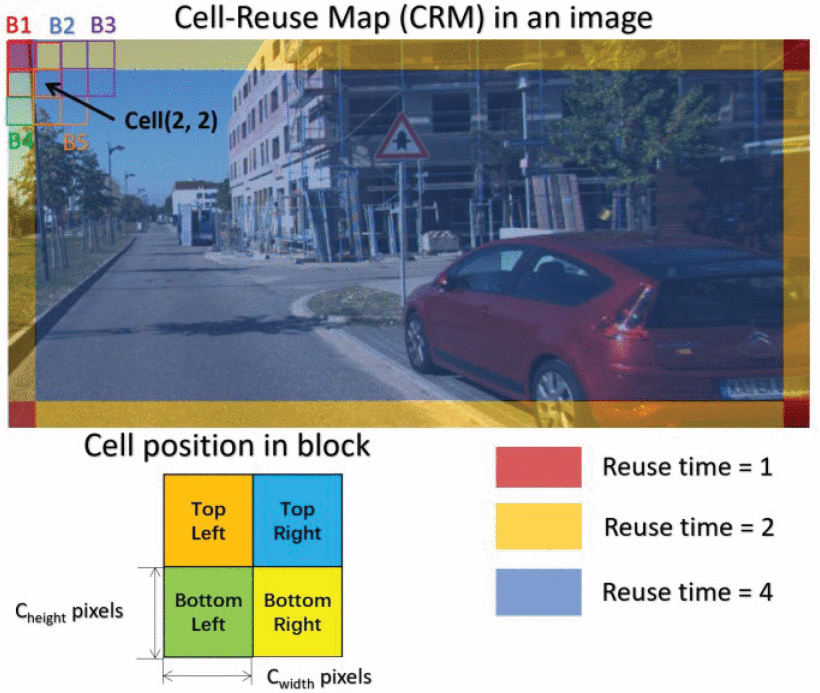 A multi-class objects detection coprocessor with dual feature space and weighted softmaxZhihua Xiao, Peng Xu , Xianglong Wang , Lei Chen , and Fengwei AnIEEE Transactions on Circuits and Systems II: Express Briefs, Jul 2020
A multi-class objects detection coprocessor with dual feature space and weighted softmaxZhihua Xiao, Peng Xu , Xianglong Wang , Lei Chen , and Fengwei AnIEEE Transactions on Circuits and Systems II: Express Briefs, Jul 2020A critical mission for mobile robot vision is to detect and classify different objects with low power consumption. In this brief, a multi-class object detection coprocessor is proposed by using the Histogram of Oriented Gradient (HOG) and Local Binary Pattern (LBP) together with a weighted Softmax classifier. Its architecture is compact and hardware-friendly suitable for energy-constrained applications. Firstly, the cell-based feature extraction unit and block-level normalization reuse the SRAMs for storing one-row cell and one-row block. Meanwhile, the working frequency of the feature extraction and block-normalization unit is synchronized to the image sensor for low dynamic power. Then, a block-level one-time sliding-detection-window (OTSDW) mechanism is developed for partial classification with scalable object size. Finally, the Softmax classifier, which is implemented by the look-up table, linear fitting methods, and the fixed-point number, is tested in the Fashion MNIST dataset to evaluate its performance in multi-class classification problems and it reached an accuracy of over 86.2% with 10,180 parameters. The experimental result shows that the hardware-resource usage of the FPGA implementation is capable of 60 fps VGA video with 80.98 mW power consumption. This method uses similar or even fewer hardware resources than that of previous work using only the HOG feature and single-class classifier.
2019
-
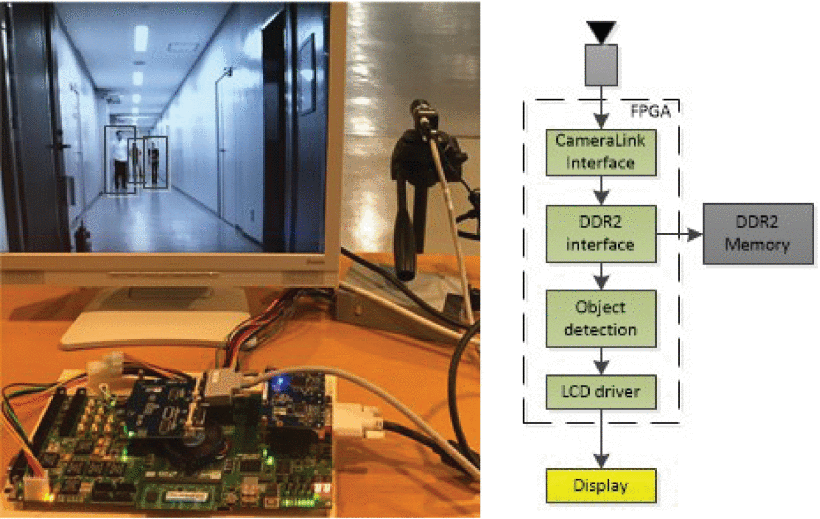 FPGA-based object detection processor with HOG feature and SVM classifierFengwei An , Peng Xu , Zhihua Xiao, and Chao WangIn 2019 32nd IEEE International System-on-Chip Conference (SOCC) , Jul 2019
FPGA-based object detection processor with HOG feature and SVM classifierFengwei An , Peng Xu , Zhihua Xiao, and Chao WangIn 2019 32nd IEEE International System-on-Chip Conference (SOCC) , Jul 2019Computer vision is an important sensing technique to translate the information to decisions. In robotic applications, object detection is a critical skill to perform tasks for robots in complex environments. The deep-learning framework, e.g. You Only Look Once (YOLO), attracts much more attention recently. Moreover, it is not an optimal solution for a mobile robot since it requires a large scale of hardware resources, on-chip SRAMs, and power consumption. In this work, we report an object detection processor synchronizing the image sensor in FPGA with a cellbased histogram of oriented gradient (HOG) feature descriptor and support vector machine (SVM) classifier by parallel sliding window mechanism. The HOG feature extraction circuitry with pixel-based pipelined architecture constructs the cell-based feature vectors for parallelizing partial SVM-based classification in multiple sliding windows. The SVM classification produces the final result after accumulating the vector components in one sliding window. This framework can be used to both localize and recognize multiple objects in video footage. The proposed object processor, in which the SVM classifier is trained by INRIA datasets, is implemented and verified on Intel Stratix IV FPGA for the pedestrian.